매일경제 김중태님의 기고문입니다.
http://news.nate.com/Service/natenews/ShellView.asp?LinkID=9&ArticleID=2006010618013024101
대표적인 검색엔진인 구글을 가지고 “국내에서 성공할 수 없는 이유”를 들며 검색결과가 형편없다는 이유를 들었습니다.
여기까지는 구글이 단지 로봇의 성능이 떨어지거나 해서 검색결과가 즐이라는 말을 하는 것 같아 평소 구글의 검색결과에 매우 흡족해 하던 저의 생각을 정면적으로 부정했습니다.
‘…미친거 아이가?’
하면서 봤습니다. 허나 자세히 보니 거의 반어법적인 것이더군요. 여기서 구글의 국내웹 검색결과가 “구글 검색 결과가 형편 없는 이유, 국내 사이트들이 검색을 막았기 때문”이라고 정의했습니다. 그 이유를 들어보면…
이런 방법은 robots.txt라는 파일에서 그 정도를 규정할 수 있음으로 인해 자신의 서버의 어느 부분을 공개하고 거부할 수 있는지 설정할 수 있습니다. 그런데 국내 유명 사이트와 검색엔진은 다른 사이트의 내용을 수집하는 주제에 자기 사이트의 내용은 수집하지 못하게 하는 어이없는 상황을 연출하고 있습니다.
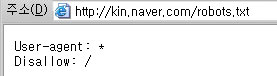
정말 이런 기사를 읽고 한가지를 시사하게 합니다.
….놀부심보
허나 기사처럼 못찾지는 않습니다. 문제는 구글이 자연어 검색을 지원하지 않기 때문에 저렇게 자연어 검색을 하면 검색을 하지 못하는 것인데, 그렇다면 자연어형식을 피하면 됩니다. 예를 들어 “장서희 부은 얼굴”이라면 “장서희 얼굴” 같은 식으로 찾을 수 있습니다.
이미지검색이 아니라 일반 검색에서라면 굳이 자연어 검색을 일부러 안써도 찾기는 쉽습니다. 한번에 찾는군요.
한번에 제대로된 결과를 찾지 못하는 것은 네이버같은 국내 검색엔진이나 구글에서나 같기 때문에 문제가 되리라곤 보지 않습니다.
여러분은 어떻게 생각하십니까?
덧. 첫눈인가 하는 최근에 생긴 검색 엔진도 네이버와 같은 차단을 하고 있음을 알아냈습니다.
자기는 되고 남은 안되고..역시 막강한 한국 기술력 ㅋ
개인적으로 필요에 의해서 한국 관련된 쪽으로는 주로 네이버를 쓰고 학교 공부 하는데는 네이버 구글 양쪽 다 씁니다. 자료의 질이나 정확도는 네이버쪽에 손을 들어주고 싶고 양은 구글쪽에 손을 들어주겠습니다.
전 검색단어가 거의 구글에 맞추어져 있어서 관련 결과가 네이버같은 곳보다 구글이 양이나 질이나 훨씬 낫더군요.
게다가 제가 자연어 검색같은걸 잘 안씁니다. -_-
내용과는 별상관없지만, 김중태씨를 매일경제신문 기자로 적으셨는데 그분은 그 신문의 기자가 아니고, 기고를 했을 뿐입니다.
고쳤습니다.